数据库查询中的exists与in分析比较
最近在用Laravel的ORM写数据库查询时,用到了whereHas的写法,这个写法的背后实现的SQL语句就是select * from `table1` where exists(select * from `table2` where table1.id = table2.table1_id),于是就查清楚了一下exists的用法和特点,在这里记录一下。
exists的用法
以下图的两张表关系作为分析: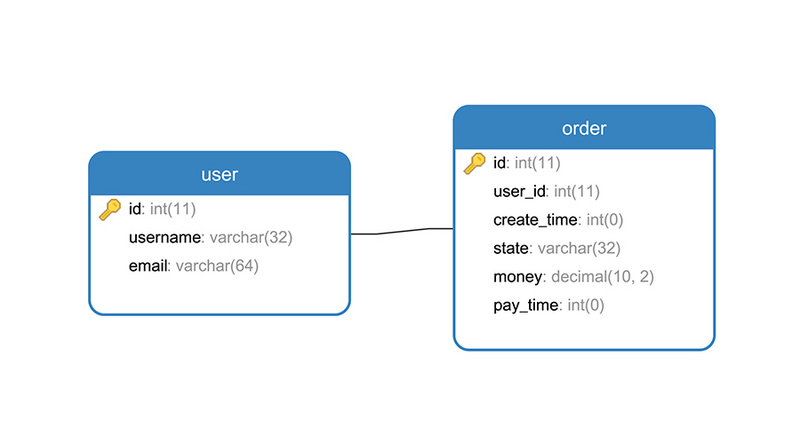
exists表示存在,它常常和子查询配合使用。例如对于上图,写下下面的SQL语句
SELECT FROM `user`
WHERE exists (SELECT FROM `order` WHERE user.id = order.user_id)
在这里,exists用于检查查询子查询语句是否会至少返回一行数据,如果有返回数据,则返回值是true,反之是false。
放子查询返回为true时,则外层的查询语句将进行查询,反之,外层查询语句将不进行查询或者查不出任何记录。
因此:上面的SQL所实现的意义在于,搜索出所有下过单的会员。
exists和in的区别和使用场景
除了exitst,in的使用也可以实现上面语句的效果。如下:
SELECT * FROM `user` WHERE id in (SELECT user_id FROM `order`)
那么,它们之间有什么区别呢。
- in()语句只会执行一次,它查出order表中的所有user_id字段并且缓存起来,之后,检查user表的id是否和order表中的user_id相当,如果相等则加入结果期,直到遍历完user的所有记录。用程序来表示如下:
1 | $result = []; |
显而易见:当order表比user表大很多的时候,使用exists是再恰当不过了,它没有那么多遍历操作,只需要再执行一次查询就行。查询次数的多少完全取决于user表的记录条数。
但是:如果说user表有10000条记录,order表有100条记录,那么exists()还是执行10000次,反而不如使用in()遍历10000*100次,因为in()是在内存里遍历,而exists()需要查询数据库,我们都知道查询数据库所消耗的性能比较大,而操作内存的话会比较快.
因此,可以得出总结:
若外层查询表小于子查询表,则用exists。
若外层查询表(记录条数很多)远大于子查询表,则考虑用in。