当我们在谈索引的时候,我们在谈什么
一句话总结:在 InnoDB 里,一个索引就是一棵 B+ 树。
那么这个 B+ 树是什么样子的呢?
数据存储在叶子节点,中间节点存目录项。
那么,
叶子节点啥样的?
中间节点啥样的?
要知道节点的结构,就得先知道 InnoDB 管理存储空间的基本单位 —— 页。
InnoDB 引擎将数据划分为若干个页,以页作为磁盘和内存之间交互的基本单位,页的大小一般为 16 KB。InnoDB 设计了许多种不同类型的页,比如存放表数据记录的页,存放表空间头部信息的页,存放 Insert Buffer 信息的页,存放 undo 日志的页等等,而这之中存放表中索引数据记录的页即数据页就是 B+ 数的叶子节点。
数据页
数据页中由多个部分组成,不同部分有不同的作用,其结构如下图:
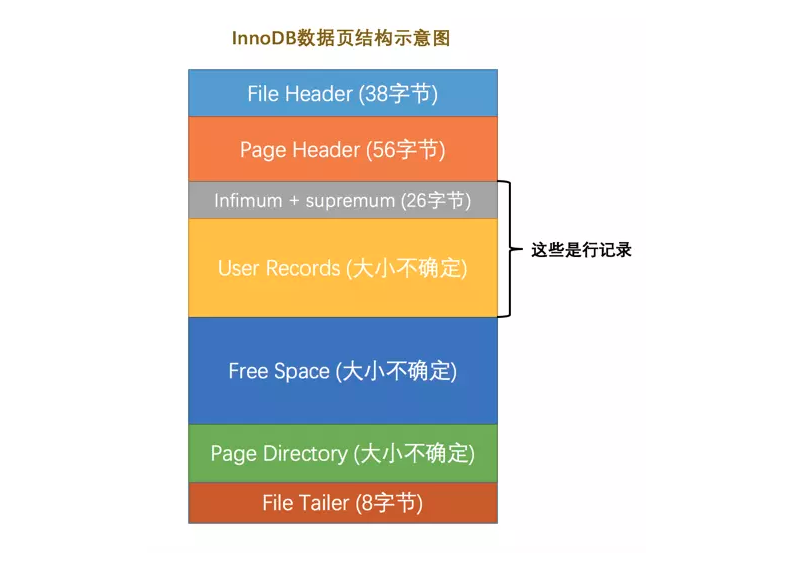
其中,各个部分的作用如下:
- File Header
File Header 是各种类型的页都有的部分,它描述了一些针对各种页都通用的一些信息,比方说这个页的编号是多少,它的上一个页、下一个页分别是谁等信息。通过 File Header 存储的上一页下一页的信息,各个数据页可以组成一种双向链表的结构。
- Page Header
Page Header 用来存储本页中已经存储了多少条记录,第一条记录的地址是什么,页目录中存储了多少个槽等。
- Infimum + Supremum
InnoDB 定义的两条分别为最小记录与最大记录的伪记录
- User Records
User Records 插入数据库的记录存储的地方,一开始生成页的时候,并没有 User Records 这部分,每当插入一条记录后,都会从 Free Space 部分申请一个记录大小的空间划分到 User Records 部分,当插入的记录越来越多导致 Free Space 用完之后,也就意味着这个也使用完了,要再插入新记录,就需要申请新的页了。每条记录通过 next_record 属性记录着下一条记录的地址偏移量,即所有记录实际上是一个单向链表的结构。记录里的 record_type 属性值为 0。
- Page Directory
为了便于查找, InnoDB 将 User Records 里的记录划分为多个组,每个组的最后一条记录的地址偏移量取出来放在 Page Directory 中,这个地址偏移量被称为槽(Slot),所以 Page Directory 就是由槽组成的。
所以在页中要查找一条记录的过程是:通过主键值用二分法确定要查找的记录位于哪个槽所对应的组中,在对应的组里遍历(每个组里包含的记录只能是 1 ~ 8 条)找到对应的记录。
- File Trailer
File Trailer 是用来校验页是否完整的,确保数据在内存和磁盘间同步不会有差错。
以上就是数据页的结构,所以,索引的叶子节点就是存有被设为索引的记录的数据页。
索引的结构
上面说到数据页之间是通过 File Header 里记录的信息来找到上一页和下一页的信息,那么如何找到第一页呢?这里就得需要有目录项了,每个目录项包括两个部分:页的用户记录中最小的主键值和页号。因为存储的记录会很多导致目录项也很多,所以为了方便对目录项进行存放和管理,InnoDB 目录项的结构设计是跟数据页一样的,不同的是其中保存记录的部分存放的是目录的信息,即目录的主键和其页号,且记录里的record_type 属性值为 1。
目录指向叶子节点的的示意图如下:
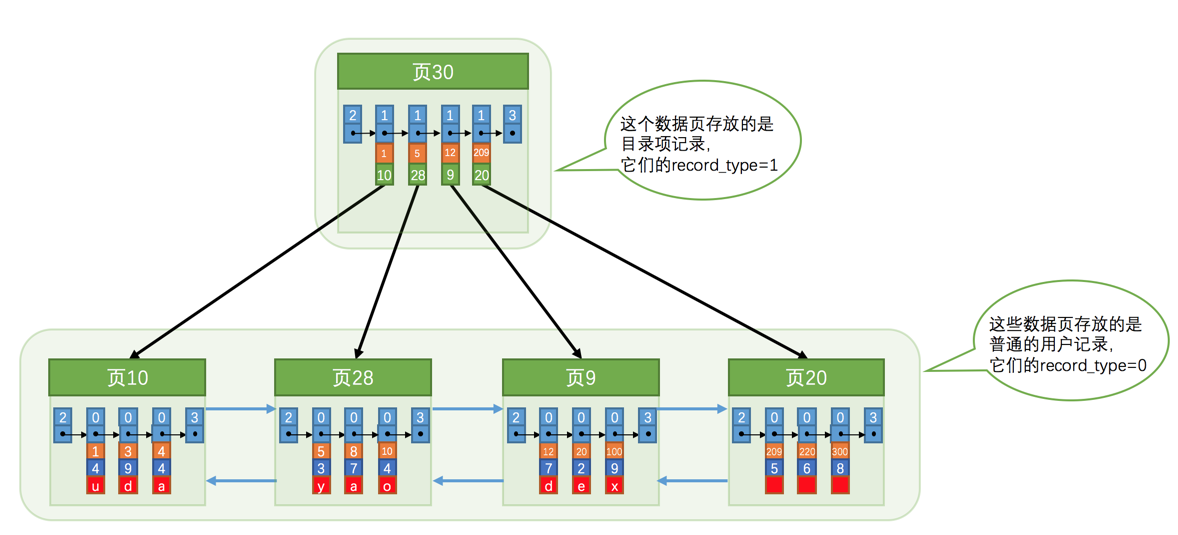
当存储的记录越来越多导致目录项越来越多时,要查找一个目录项就变得越来越不容易,此时,就需要有指向目录项的目录了,于是一直演变下去就会出现多级目录,形成数据的索引,而这个多级目录就是一个树的结构,如下图所示:
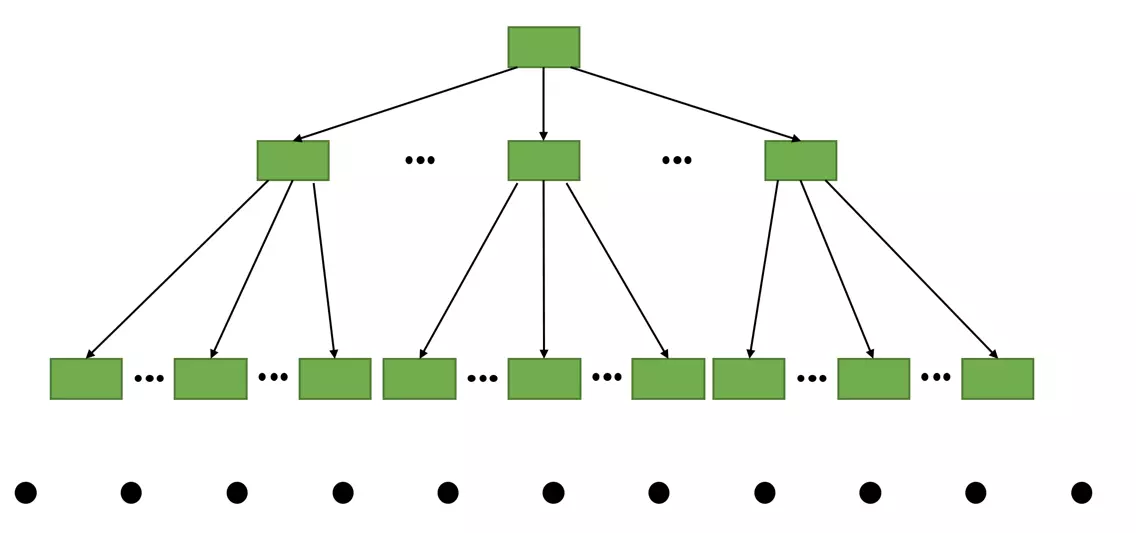
在 InnoDB 里这种树叫 B+ 树,所谓的索引就是长这样。